Without a doubt ELB is the simplest load balancing solution on AWS, however it may not be suitable for all users given it doesn’t support features such as a static IP. Fortunately OpsWorks makes it only marginally more complicated to set up HAProxy as an alternative.
The AWS ecosystem encourages you to implement redundancy across availability zones and to avoid a single point of failure (SPOF). HAProxy will give you many additional features over ELB, however it is difficult to achieve cross-zone redundancy and automated failover as supported natively by ELB. DNS round-robbin can help balance load across multiple HAProxy instances to achieve scalability, however this solution does not help to achieve high availability.
This blog post will demonstrate how to implement automated failover using a self-monitoring pair of HAProxy instances in an active/standby configuration. When a failure is detected the healthy standby will automatically take control of the elastic IP (EIP) assigned to the pair and ensure the service can continue to function. A notification will also be triggered via SNS to alert you that a failover has taken place.
Getting started
I’ll assume you’re starting with a working OpsWorks stack including both an application server and HAProxy layer. I recommend disabling automatic assignment of an EIP in the HAProxy layer settings (make sure public address assignment is enabled though) then manually register a single EIP with your stack and assign it to one of your HAProxy instances. I’ll also assume you have a custom cookbook repository setup. Also, I’ll assume you have a pre-existing SNS topic for failover notifications to be published to.
Chef recipe
Create the following files within a custom cookbook:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 4 5 6 7 8 | |
Add the haproxyfailover::setup recipe to the setup lifecycle event of your HAProxy layer.
IAM permissions
Next you need to add additional policies to the EC2 IAM role used by your HAProxy instances. There’s more details on finding your instance role in one of my previous posts.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Don’t forget to replace <my stack ID> and <my SNS ARN> with your own values.
Editing custom stack JSON
Edit your stack settings and add the following to your custom JSON.
1 2 3 4 5 6 | |
Don’t forget to replace <my EIP> and <my SNS ARN> with your own values. Afterwards your custom JSON
should look something like this:

Testing failover
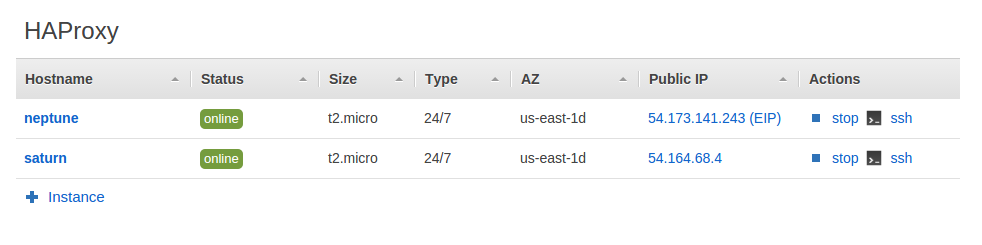
After running the setup event again we’re now ready to test our failover. You’ll see that 54.173.141.243 is assigned to neptune initially:
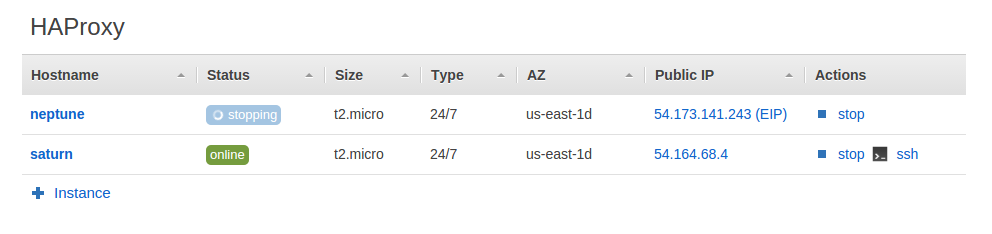
After stopping neptune 54.173.141.243 is still assigned to it because the failover hasn’t triggered yet:
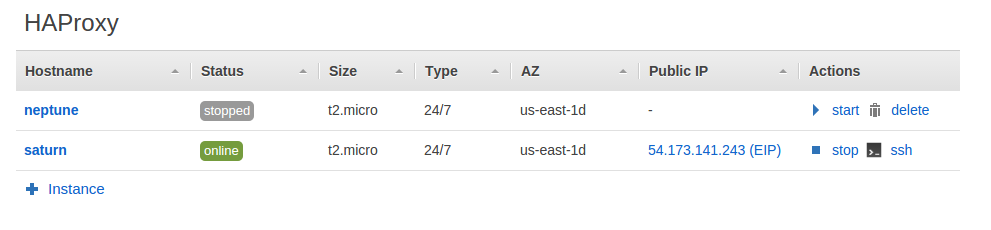
Once the failover triggers 54.173.141.243 is now assigned to saturn:
Also the following notification is received:

Saturn will retain the IP even if neptune is brought back online, unless it is manually reassigned or saturn fails.
Discussion
Use of monit
monit is used on each instance to check that the primary IP is online. The OpsWorks agent itself uses monit and therefore it doesn’t need to be installed on the instance. In the default OpsWorks configuration monit runs every 60 seconds. monit has a built in email alerting function, however in my opinion SNS is more manageable as alert recipients can easily be updated via the AWS console.
Failover delay
The monit configuration above specifies for 3 cycles, meaning that a failover won’t be triggered unless
3 consecutive monit runs fail. Therefore a failover could take about 4 minutes. This is an acceptable trade-off in most
scenarios as a failover should be rare and you’d rather avoid failing over unnecessarily for an issue that resolves itself
within a minute or two. You can however remove the for 3 cycles line to failover immediately if you’d prefer.
Checking external IP
To avoid the active instance attempting to failover to itself it first checks
its IP against http://checkip.amazonaws.com when a failover occurs. An instance will only attempt to take over if the
external IP returned isn’t the primary IP. This also serves to verify the instance taking over has external connectivity,
otherwise it might attempt to take over the IP when its own connectivity is causing the health check to fail.