In a system dealing with user generated images it’s common to have to resize images before they can be served to the web. Storing and serving large quantities of user generated images can also be a challenge – that is unless you’re using AWS S3. A typical implementation using S3 to store and serve images requires images to be resized into every required size and saved to S3 upon being uploaded. An unfortunate limitation of this technique is that you must know all required sizes at the time the image is uploaded – something that may not be constant, consistent or known in some (particularly legacy) applications.
One solution is to automatically resize images the first time they’re requested using dimensions provided in the image URL, this way the application requesting the image can choose an appropriate size. While S3 doesn’t provide functionality to transparently proxy image misses to your image processor, it is possible to use S3 S3 routing rules to achieve a similar function.
Overview
Using routing rules it’s possible to return a 302 redirect whenever a 404 error occurs, this 302 redirect can then take the user to your EC2 instance which resizes the image, serves it to them then saves the resized copy back to the original bucket so future visitors won’t be redirected.
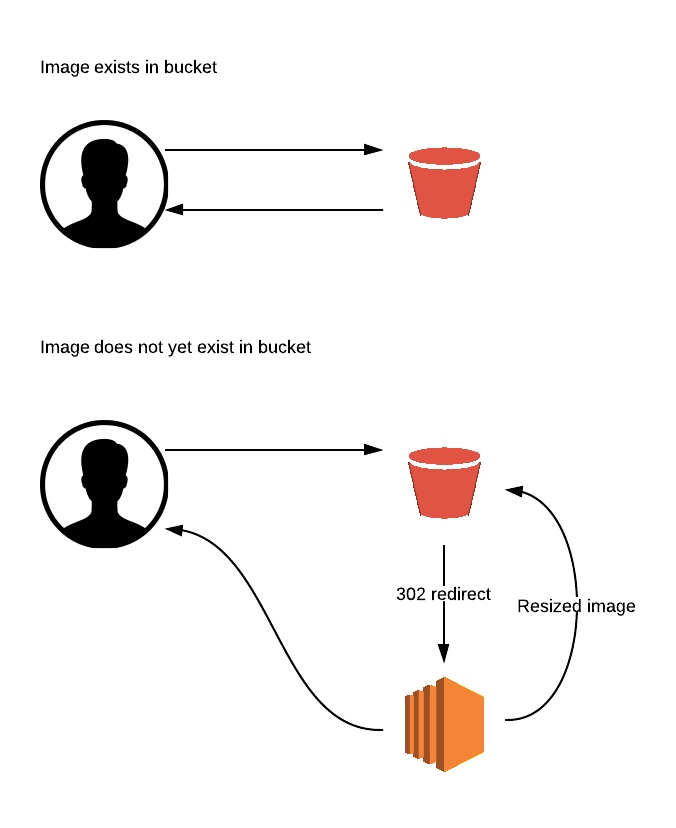
Implementation
First, it’s assumed that you have a bucket setup to serve its content publicly on one domain and your processing
server on another. Both domains must use the same URL structure for images aside from the host name, so for example
images.domain.com/widgets/myimage_600_400.jpg and process.domain.com/widgets/myimage_600_400.jpg
should both work (assuming images.mydomain.com is the bucket and process.mydomain.com is the processor).
When receiving a request process.mydomain.com should resize the image (most likely after obtaining the
image from another private bucket for originals), serve that image to the visitor then save it back to
the images.mydomain.com bucket.
Next – go to the bucket in the S3 console, go to the bucket properties and enter the following routing rules in the ‘Enable website hosting’ accordion menu:
1 2 3 4 5 6 7 8 9 10 11 | |
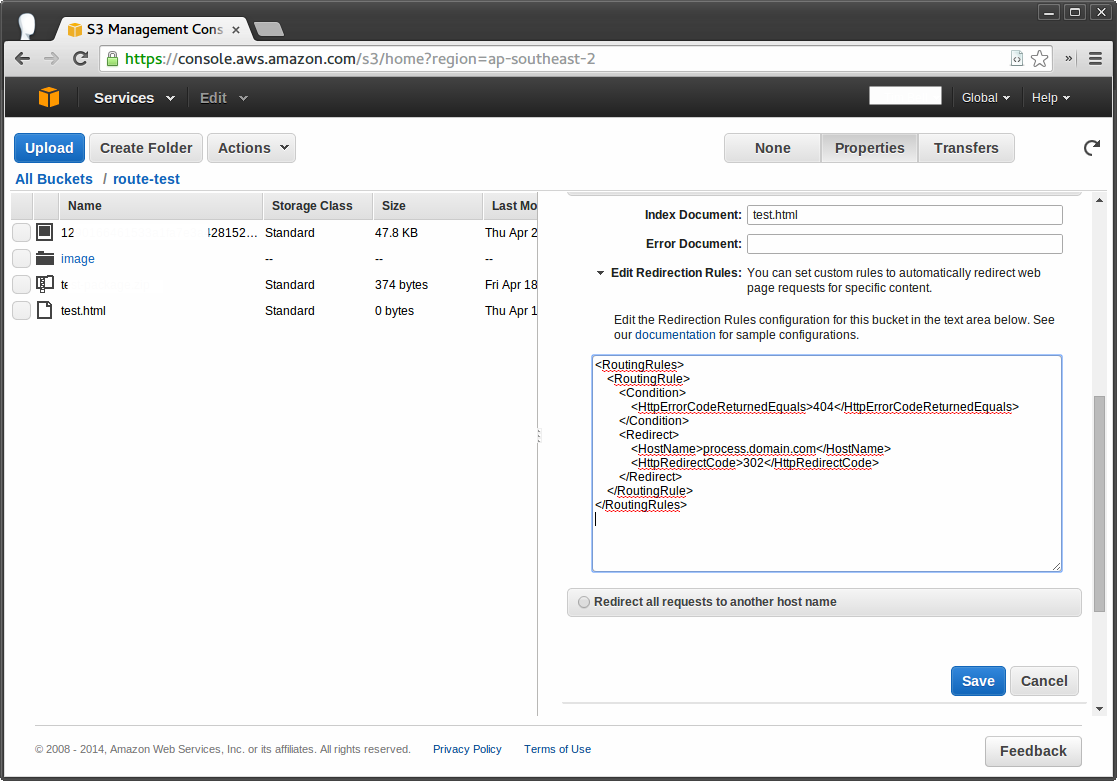
You now have lazy image processing!
Enter CloudFront
S3 is a reasonably effective CDN (in the sense that it offloads serving images), but it’s not geographically
distributed and if you’re serving images to visitors across the globe you may wish to also implement CloudFront.
Unfortunately you can’t simply setup CloudFront to use the images.mydomain.com bucket as an origin because
CloudFront will cache the 302 redirects for a minimum of 60 minutes – meaning your image processor might process the same image many times.
One solution is to put a second CloudFront distribution in front of process.domain.com and set the S3
redirect to use that CloudFront endpoint rather than the processor directly. In this scenario the first region to receive
a request will pass through the first CloudFront distribution, the S3 bucket, the second CloudFront distribution
and then hit the processor. The second request from that same region should then hit the second CloudFront distribution
as will every other request from this region until the 302 redirect expires.
Users making requests from other regions after the first request won’t have the 302 redirect in the cache for their region
so they should hit the file in the S3 bucket which will then get cached in their region.
Caveats
While this approach is certainly effective in some scenarios it’s not exactly elegant. Be sure to first consider whether CloudFront alone or resizing images in advance would work better in your situation. It’s also worth keeping in mind that all genuine 404 requests (that is for images which don’t exist at all) will get passed to your server and won’t be offloaded to S3.
Be careful when lazy processing images in general – if you don’t implement some form of rate limiting you may end up being vulnerable to a Denial of Service attack if someone were to try and request thousands of images in different sizes.