Update: CodePipeline now has built-in support for both Lambda and OpsWorks. I’d now recommend using the built-in functionality rather than the method described in this post.
Original post:
AWS recently released CodePipeline after announcing it last year. After doing the setup walkthrough I was surprised to see only the following deployment options!
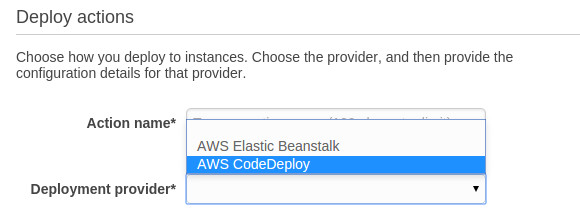
I’m sure other integrations are in the works, but fortunately CodePipeline supports custom actions allowing you to build your own integrations in the mean time.
If you were hoping to see this:
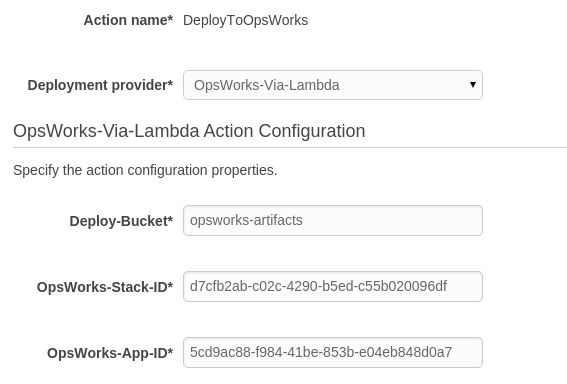
Then read on!
I’ve implemented a custom action to deploy to OpsWorks using Lambda, you can find the full source of the Lambda function on GitHub. It leverages the fact that CodePipeline uses S3 to store artifacts between stages to trigger the Lambda function, and SNS retry behaviour for polling.
This blog posts explains how to configure your pipleine and the Lambda function to deploy to OpsWorks using CodePipeline.